Guided diffusion sampling with evolutionary search
Diffusion-ES leverages gradient-free evolutionary search to perform reward-guided sampling from trained diffusion models. An initial population of trajectories is generated by sampling from our diffusion model. At each iteration, we score (clean) trajectories with our reward function, select the highest reward samples, and mutate them.
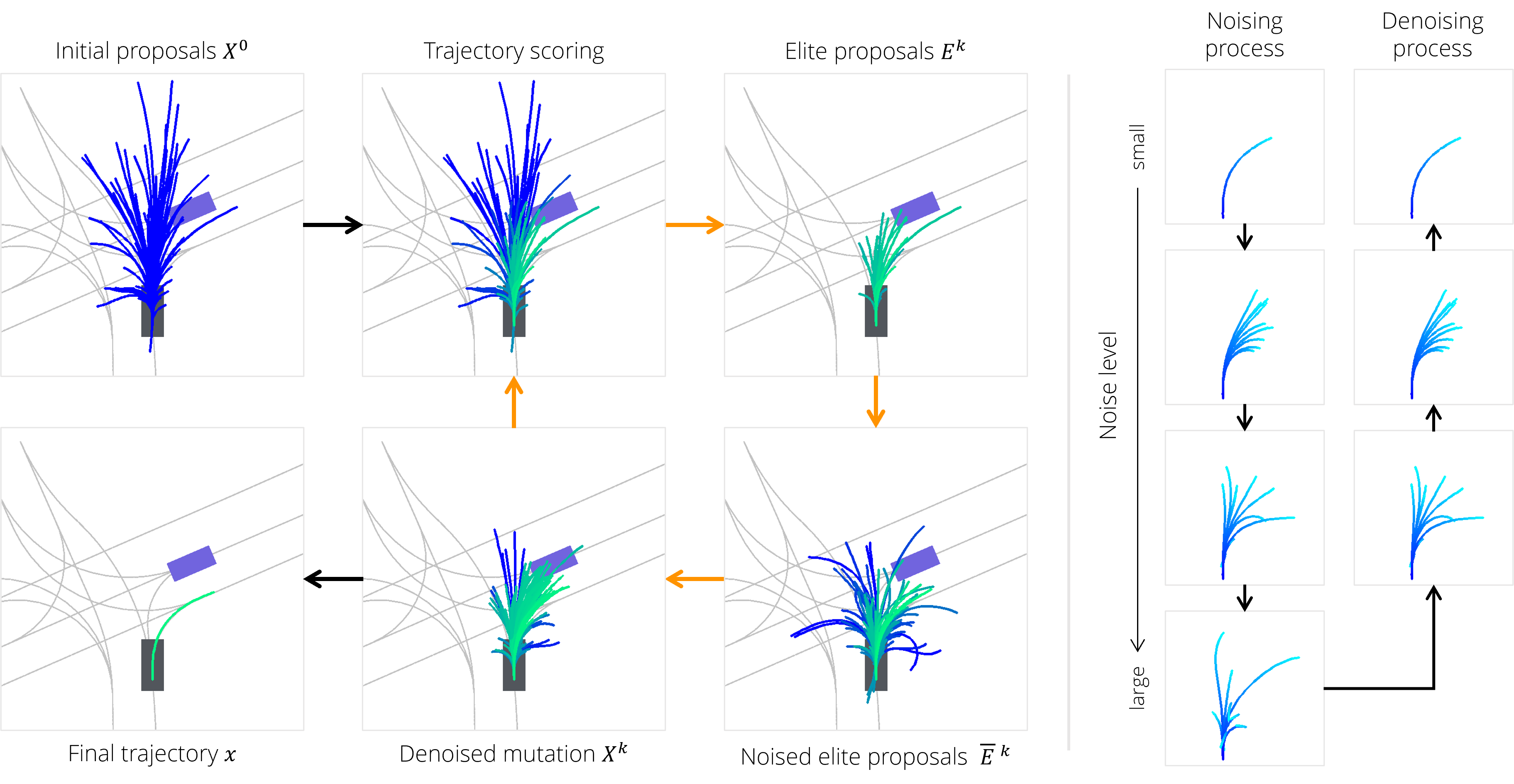
Our key insight is that we can leverage a truncated diffusion process to mutate trajectories while staying on the data manifold. We can run the first t steps of the forward diffusion process to get noised samples, and then run t steps of the reverse diffusion process to denoise the samples again. We only need a small fraction of the total number of diffusion steps to perform mutations this way, which makes our sampling-based optimization much more efficient.
Closed-loop planning for driving in nuPlan
We validate our approach by using black-box planning rewards to guide a trajectory diffusion model. Specifically, we adopt the scorer used in PDM-Closed, with small tweaks to handle more diverse trajectory proposals. Diffusion-ES achieves state-of-the-art performance in nuPlan, a closed-loop driving benchmark.
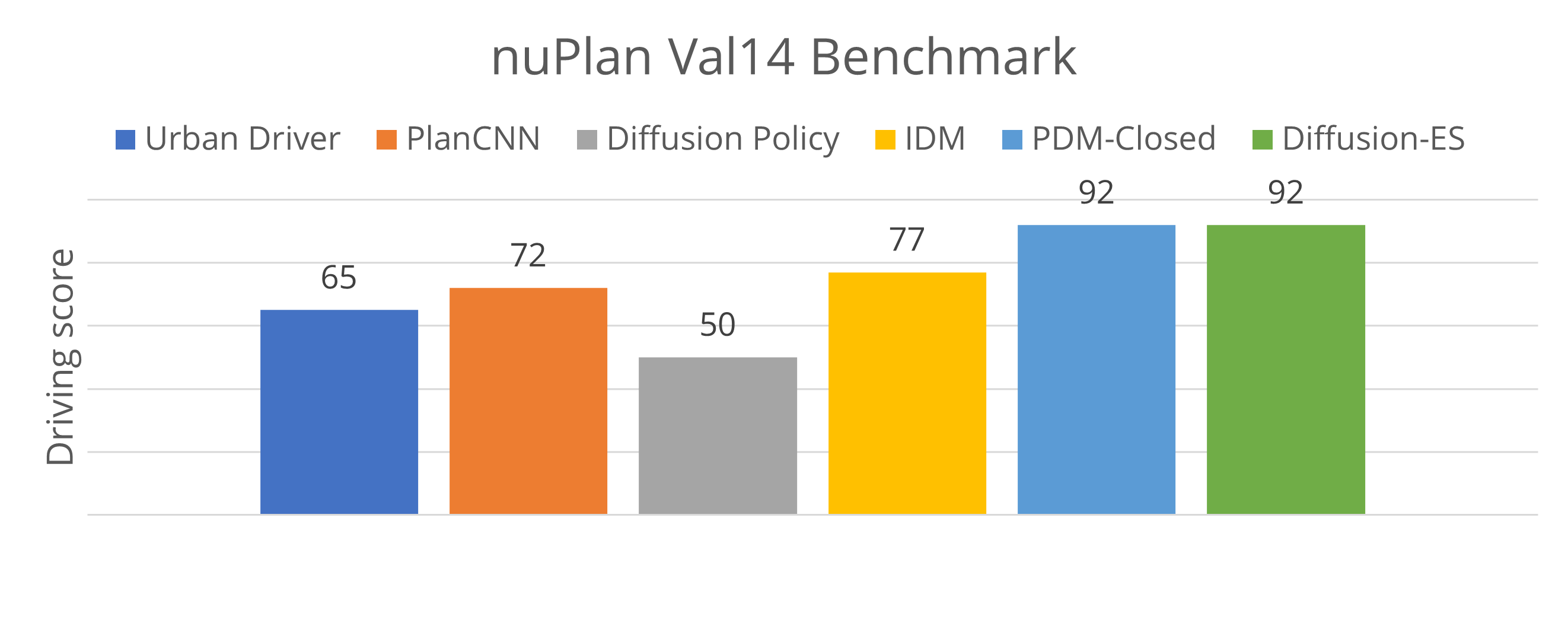
Our planner can navigate challenging urban driving scenarios with dense traffic, outperforming prior learning-based methods and matching rule-based planners. Unlike prior work, our method can navigate environments more assertively, performing unprotected turns and changing lanes without dense waypoint guidance.
Instruction following in nuPlan
Diffusion-ES can be used to optimize arbitrary reward functions at test-time without retraining. To highlight this capability, we use few-shot LLM prompting to synthesize novel reward functions which execute langauge instructions, and then optimize those reward functions online with our method. This allows us to execute arbitrary language instructions without additional training.

Similar to prior work, we expose a Python API which contains reward-shaping methods. These methods can be invoked to alter the behavior of the base reward function, e.g., adding a dense lane following reward. We provide paired examples of language instructions and corresponding programs which use the provided API. Then we can prompt an LLM (GPT-4) with those examples and novel language instructions to automatically generate programs at test-time.
We also report quantitative performance for instruction following on a suite of language controllability tasks. Task success is determined by whether the provided instruction is followed and the scenario objective is accomplished.

We find that although rule-based methods achieve strong results on the original nuPlan benchmark, they struggle with more complex scenarios which require changing lanes and driving assertively.
BibTeX
@misc{yang2024diffusiones,
title={Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous Driving and Zero-Shot Instruction Following},
author={Brian Yang and Huangyuan Su and Nikolaos Gkanatsios and Tsung-Wei Ke and Ayush Jain and Jeff Schneider and Katerina Fragkiadaki},
year={2024},
eprint={2402.06559},
archivePrefix={arXiv},
primaryClass={cs.LG}
}